Data-310-Public-Raposo
Data 310 project summaries
7.28.20 Class Exercise:
Word Embeddings:
- One-hot encoding is an ecoding method that represents words (or parts of words) in 1 demensional vectors. Each position in the vector represents a word/word fragment in the vocabulary. Each position in the vector contains a zero if the word does not match the associated entry in the vocabular or a one if the word does match the associated voacbulary entry. In vectorizing a corpus of words, one-hot encoding in not a good choice as the encoder because the vocabulary is likely very long so you will end up with equally long vectors. These vectors also indicate nothing about the relative meaning of each word since vocabulary organizes words based on frequency of appearance in the tokenizing data. In such cases when the meaning of words and comparing the similarity of words is important, a superior method of encoding is four dimensional embedding (4DE). 4DE represents each word as a 4-dimensional vector. These vectors can be used to find similarities in groups of words. For exmaple, consider the following:
Man –> Woman as King –> ???. The answer is queen and by training a model using 4DE data, it can predict this using a little “mathemagic”. We know there is a relation between the words man and woman so if we subtract their 4D vectors, we get a vector that describes this relation. Now, subtract the other vectors of words from the vocabularly from the vector for king. We can then compare these subtracted vectors to the one we got from man and woman. The most similar vector will be the one from subracting queen from king (example source). Below, we can visualize the perfomance of a model that used 4DE.
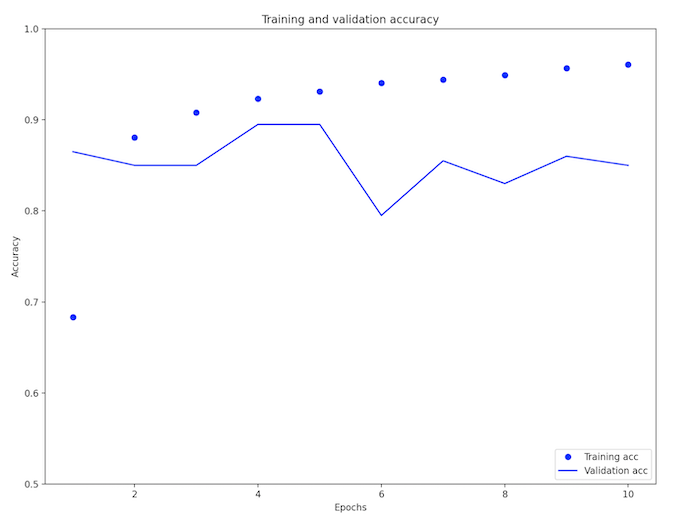
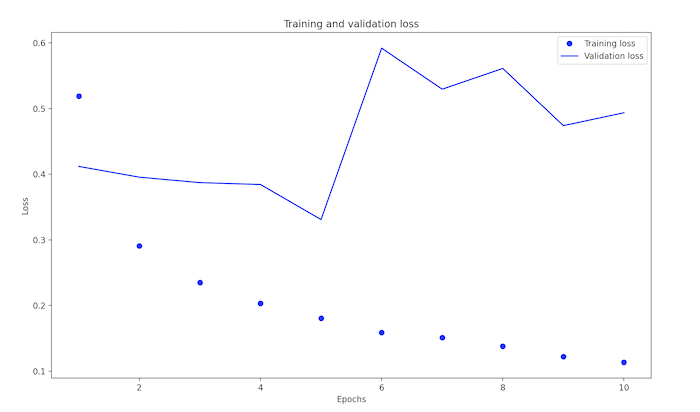
As visible in the above graphs, training accuracy and loss smoothly approach 1 and 0 respectively, however, this is not the case for the validation scores. The line of validation accuracy greatly increases and decreases eradically and shows an overall decline, suggesting overfitting. Similarly, validation loss changes eradically and increases singificantly over epochs. This overfitting is likely becuase of a large vocabulary size (because the model spends equal time learning uncommon words as it does the more relevant, common ones).

The above visualization of the embeddings displays (using PCA and tSNE dimensionality techniques so we can visualize datapoints originally in hundreds of dimensions) word relations. Points that are closer to eachother represent words with similar meaning (their 4DE vectors are similar). In this case, since some words are split into fragments, not all of this clustering makes sense. These plots are a way to visualize the relation between words that the model assigns using embedding.
Text Classification with an RNN:
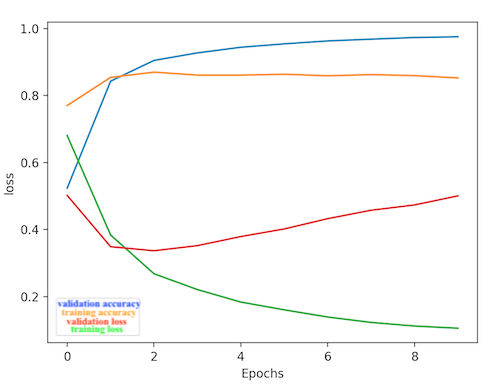
- Below are graphs of model performance for a text classification RNN model. LSTM layers help improve RNN performance by “passing on information as it propagates forward” (source). This improvement is evident in the overall lower loss and higher validation on the RNN that used LSTM layers.
Without LSTM:
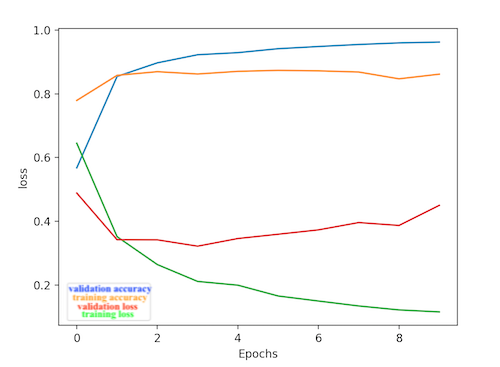
With LSTM: