Data-310-Public-Raposo
Data 310 project summaries
7.21.20: Class Exercise
A. Premade estimators:
-
How did you split the labels from the training set? What was the name of the labels dataset?
The training and testing data was read in from 2 seperate csv files. In the training data, we then split out the ‘species’ label becuase this is what we want our model to predict. The data contains features and labels. The features are different measures (in this case about flowers) of a datapoint and the labels are the datapoint’s true classification. The labels datasets are named train_y and test_y, which contain the species classifications of each datapoint in both the training and testing sets. -
List 5 different estimators from tf.estimator and include the base command as you would write it in a script (for example this script used the tf.estimator.DNNClassifier() function from the API).
Estimators are functions that estimate the results of a model based on training data. Different estimators look for different patterns in the data. Below are 5 examples of estimators:
DNNClassifier
classifier = tf.estimator.DNNClassifier(
hidden_units, feature_columns, model_dir=None, n_classes=2, weight_column=None,
label_vocabulary=None, optimizer=’Adagrad’, activation_fn=tf.nn.relu,
dropout=None, config=None, warm_start_from=None,
loss_reduction=losses_utils.ReductionV2.SUM_OVER_BATCH_SIZE, batch_norm=False)
DNNLinearCombinedClassifier
classifier = tf.estimator.DNNLinearCombinedClassifier(
model_dir=None, linear_feature_columns=None, linear_optimizer=’Ftrl’,
dnn_feature_columns=None, dnn_optimizer=’Adagrad’, dnn_hidden_units=None,
dnn_activation_fn=tf.nn.relu, dnn_dropout=None, n_classes=2, weight_column=None,
label_vocabulary=None, config=None, warm_start_from=None,
loss_reduction=losses_utils.ReductionV2.SUM_OVER_BATCH_SIZE, batch_norm=False,
linear_sparse_combiner=’sum’)
LinearClassifier
classifier = tf.estimator.LinearClassifier(
feature_columns, model_dir=None, n_classes=2, weight_column=None,
label_vocabulary=None, optimizer=’Ftrl’, config=None, warm_start_from=None,
loss_reduction=losses_utils.ReductionV2.SUM_OVER_BATCH_SIZE,
sparse_combiner=’sum’)
LinearRegressor
regressor = tf.estimator.LinearRegressor(
feature_columns, model_dir=None, label_dimension=1, weight_column=None,
optimizer=’Ftrl’, config=None, warm_start_from=None,
loss_reduction=losses_utils.ReductionV2.SUM_OVER_BATCH_SIZE,
sparse_combiner=’sum’)
train_and_evaluate
trainer = tf.estimator.train_and_evaluate(
estimator, train_spec, eval_spec)
-
What are the purposes input functions and defining feature columns?
Input functions allocate data for training, testing, and predicting by creating small datasets. These datasets contains two elements- features and a label. Features is a python dictionary that contains the data’s feature names (as keys). Each key is mapped to array that contains the corresponding values of each feature. The label is an array containing the values of the label for every example contained in the features dictionary. Feature columns is an object that describes how the estimator model should use the raw data passed into it. In other words, feature columns give meaning to raw data by mapping the data to specific features, which the estimator can interpret the significance of. Here is an image I found helpful in interpreting what this means.
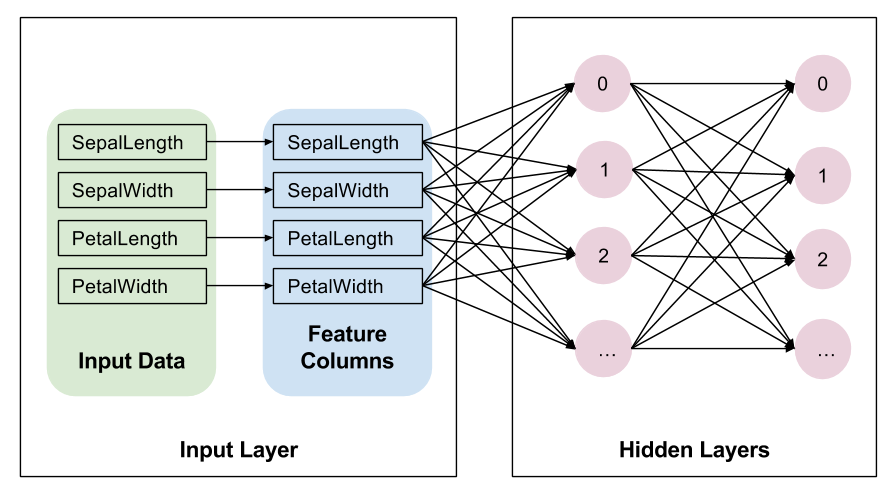
Image source -
Describe the command classifier.train() in detail. What is the classifier and how did you define it? Which nested function (and how have you defined it) are you applying to the training and test detests?
classifier.train() trains the estimator model. It has 2 imputs- input_fn and steps. input_fn = a function we defined earlier in the code, which batches our data so in this step, we call that function so the classifier is trained on batches that the function creates. Steps specifies how long (how many stops) the model should train for. - Redefine your classifier using the DNNLinearCombinedClassifier() as well as the LinearClassifier(). Retrain your model and compare the results using the three different estimators you instantiated. Rank the three estimators in terms of their performance.
Results: DNNClassifier:
Test set accuracy: 0.900
Prediction is “Setosa” (81.5%), expected “Setosa”
Prediction is “Versicolor” (45.5%), expected “Versicolor”
Prediction is “Virginica” (54.8%), expected “Virginica”
DNNLinearCombinedClassifier()
Test set accuracy: 0.733
Prediction is “Setosa” (77.4%), expected “Setosa”
Prediction is “Virginica” (45.9%), expected “Versicolor”
Prediction is “Virginica” (63.0%), expected “Virginica”
LinearClassifier.
Test set accuracy: 0.967
Prediction is “Setosa” (99.2%), expected “Setosa”
Prediction is “Versicolor” (97.3%), expected “Versicolor”
Prediction is “Virginica” (95.9%), expected “Virginica”
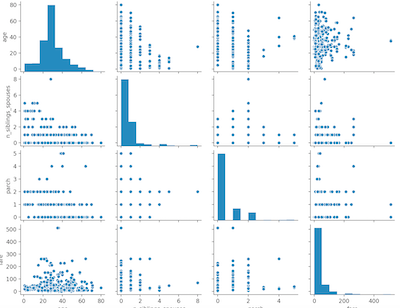
B. Build a linear model with Estimators: - Below are a histogram of the age distribution of Titanic passengers and a pairplot of data’s features (except for survival, which is the target/what we are trying to predict). The distribution of age matches its predicted probability plot found in the pairplot- I think this means that age will not contribute too much in overall loss of the model and that it is likely a good predictor of survival. Also, something to consider about this distribution is that the majority of the people on the boat (gathered form the histogram) are in their 20s-30s so they will likely comprise the majority of survivors. I wonder if a larger proportion of a different age group survived- if there were equal samples from each group, which group would have the most survivors?
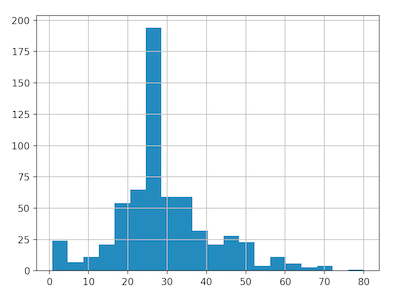
-
What is the difference between a categorial column and a dense feature?
Categorical columns have non-numeric inputs (or numeric inputs with no numerically significant value) that represent categories. In the Titanic data, for example, gender is a categorical column (‘female’ and ‘male’ are the categories). These column categorical entries can be transformed into numberic values using indicator digits (for example, use 0 = male, 1 = female to transform the column). Dense features are numeric columns with significance beyond being an indicator digit. Age, for example, represents a dense feature in this dataset. - Describe the feature columns that have been input to your LinearClassifier(). How would you assess the result from your initial output? What is the purpose of adding a cross featured column? Did your attempt to capture the interaction between age and gender and incorporate it into your model improve performance?
The feature columns are ‘sex’, ‘n_siblings_spouses’, ‘parch’, ‘class’, ‘deck’, ‘embark_town’, ‘alone’, ‘age’, ‘fare’
The dense features of the list are ‘n_siblings_spouses’, ‘parch’ (number of parents/children on board), ‘age’, ‘fare’
The categorical features are ‘sex’, ‘class’, ‘deck’, ‘embark_town’, ‘alone’
Training reports an accuracy of 0.75757575 and loss of 0.490792, which is not very good and suggests that the model may be overfit or there is simply no strong correlation between the features and survival rate.
Although the training results look grim, crossing feature columns may be able to save the day. Logically, it seems that some of these features should contribute to survival rates. Consider the following: A male and a female may have the same water-treading abilities and are therefore both as likely to survive. Similarly, it is also logical that it may be easier for a 20 year old female to tread water than an 80 year old male. As evident from this example, combining features can help unearth trends in the data that may be missed otherwise. Cross featured columns multiply the entries of the selected features, making a new column in the dataset. In the Titanic model, when crossing age and gender, the result was an improved performance in training with an accuracy of 0.7765151 and a loss of 0.46997288.
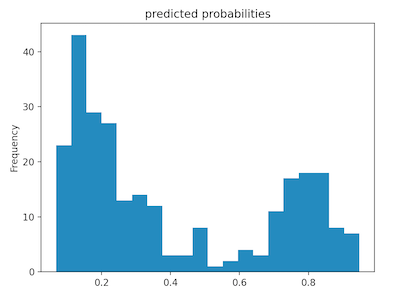
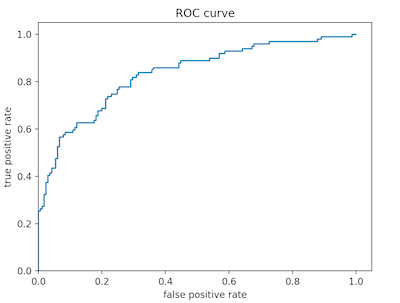
Below are graphs of the model’s predicted probabilities and the rate of change (ROC) of true and false positives in testing (a measure of accuracy in predicting survival). The predicted probabilities plot shows a binomial distribution, with the majority of people falling below 50% chance of survival. Another notable trait of the ditribution is that no individuals have 0% or 100% chance of survival. The ROC curve shows that changing rate of true and false positives in testing. The rate of change of false positives is consistently much greater than that of false negatives, however, as the rate of false positives increase the model becomes more inaccurate. This is especially true as curve begins to level off, indicating that rate of true positives is remaining relativly stable while rate of false positives keeps increasing- the model is becoming overfit.