Data-310-Public-Raposo
Data 310 project summaries
7.20.20 Class Exercise:
Final Project:
- How do prexisting medical conditions affect immune response to COVID-19?
- This question is significant becuase it can aid in targeting individual with COVID who are more likely to have a severe reposnse with early and agressive treatment. In the future, this could mean that at-risk individuals who test positive could recieve life-saving medicine, at home, weeks before their symptoms would become severe enough to warrant a hospital stay. This could also be influenctial in determining which school districts should have in-person classes- if there is a high population of at-risk students, parents, and educators, it may be advisible to consider this in any desicions. This is especially important since there was never a SARS vacciene developed for the last outbreak. My program could be useful for the student health center as we return to campus this Fall- the program could be used to determine if a student should quarantine locally (in the designated on-campus facilities) or be sent home. Also, maybe I will be able to identify specific conditions that place individuals at an increased risk for contracting COVID. The goal of my program will be to identify high-risk populations given their medical background. This process is complex given the many features my model will need to handel (particularly, the numberous medical conditions listed in the data).
- The plan: using CDC data from their COVID-NET database, I will train a CNN (similar model to the one we used on the Titanic dataset) to predict the severity of symptoms in coronavirus patients. I think it would be cool to make a gradient boosting plot like we did on the titanic data for this TF exercise that would represent how features incresed or decreased survival rate or ICU visit rate.
Cats and Dogs: - Last week, we made a model that took images as inputs and classified them as either cats or dogs. We made use of the directories within the dataset (cats and dogs) and their subdirectories (training and validation) to split the data up appropriately. From these directories, we allocated 90% of the data for training and 10% for testing. We also used a new optimizer function when building our CNN called RMSprop and set the learning rate to 0.001.
-
In training a model using a CNN, one must consider which optimizer to use. The optimizer works with the loss function by making guesses about the data, of which the loss function judges the accuracy. In the past, I’ve used either the Adam or RMSprop optimizer and, in this case, RMSprop is the ideal choice. To explain why this is true, I’ll fist explain the concept of stochastic gradient descent (SGD). SGD is the ‘guess and check’ process the optimizer and loss function complete when training a model. Depending on the weights assigned within the model, the model will have a different measure error. The goal of SGD is to reduce this error- picture an empty pond. The ground slopes up and down, there are several local minimums in the pond and one global minimum (the lowest point). This surface represents the multidimensional graph that SGD anaylyzes by ‘blindly walking around’ guessing and checking if it is at the minimum possible error. Different optimizers work better depending on the shape of this graph. Adam, for example, works best when minima are flat. RMSprop works by using a specified a learning rate to defines how the mathematical functions in the model’s transformers can learn using SGD. In other words, the learning rate defines how large of steps the function will be taking around our graph so by setting a low learning rate (0.001), we can ensure that the model does not train too quickly, which will increase accuracy (especially since we are working with the large cats and dogs dataset). Moreover, RMSprop tends to perform well on larger datasets while Adam does not.
Sources: Source 1, source 2 -
In this model, we used the binary_crossentropy loss function. As the name states, this loss function may be appropriate if we are working with binary classification data (that is, the data has 2 classes such as cats and dogs). The goal of the loss function is to evaluate how good or bad of predictions the optimizer makes during training, and penalize the model accordingly. This penality, or loss, when points are misclasified is derived from how ‘bad’ the prediction is. For example, consider a model that classifies points into groups A and B. If the point c belongs to class A, then we have 2 possible extremes for the associated cases. First, if the model predicts point c belongs to group A with a a high degree of certaintly (high predicted probability), the loss will be very low. Conversely, if the model predicts that point c belongs to class B, the predicted probability that the point is actually in A is low so the loss will be very high. As you may notice, these two measures are iversely proportional. The goal of training is to minimize the loss funtion (means we have more accuracy in making predictions)
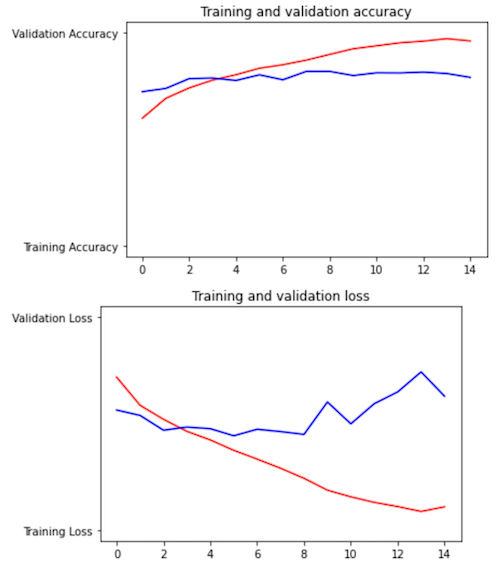
Source - In the model.compile function, we also specify a metric argument. This argument denotes which measurment will use to evaluate the model as it trains. These graphs show that as training progresses (as epochs increase), training (red) accuracy increases while loss decreases. This is the general trend of training data, however, testing (blue) accuracy remains relatively stable while loss increases. This indicates that as the number of epochs increases, the model is becoming overfit. Furthermore, my suspicion is confirmed by looking at the loss and accuracy from the last epoch of training: training loss: 0.1093, training accuracy: 0.9618, testing loss: 0.6289, and testing accuracy: 0.7907. Overfitting occurs when the model becomes too specific, meaning it ‘knows’ the training data too well, so it can’t generalize what it ‘knows’ to other data (to the testing set). By the end of training, the model is clearly overfit and it will not perform well as such.
- The innaccuracy of the model is evedent below as it misclassified all 3 cats as dogs. I became suspicious of an error somewhere but tested it again on some more ‘obvious’ cats, which it was more successful on. Since the model is overfit, I expected it to perform poorly but steps can be taken to help improve model fit. We can combat over and underfitting by training on more complete data (more representative of an entire group, only add more data if it represents new findings or you have another compelling reason to do so). If this isn’t a possibility, we can use regularization to adjust for this lack of variety or lack of sample points.
Clifford, the big red dog:
 Dog
Dog
My dog, Elsa:
 Dog
Dog
The Target dog:
 Dog
Dog
Garfield:
 Dog
Dog
Ms.Norris, from Harry Potter:
 Dog
Dog
Grumpy Cat:
 Dog
Dog
Random Cat:
 Cat
Cat
- The innaccuracy of the model is evedent below as it misclassified all 3 cats as dogs. I became suspicious of an error somewhere but tested it again on some more ‘obvious’ cats, which it was more successful on. Since the model is overfit, I expected it to perform poorly but steps can be taken to help improve model fit. We can combat over and underfitting by training on more complete data (more representative of an entire group, only add more data if it represents new findings or you have another compelling reason to do so). If this isn’t a possibility, we can use regularization to adjust for this lack of variety or lack of sample points.