Data-310-Public-Raposo
Data 310 project summaries
Question 1: ImageDataGenerator() is a command that creates subdirectories (in our case, within training and testing directories). Subdirectories are like folders within our directories that auto-label data points with class names specific to the subdirectoy. For example, if our validation data directory contained images of horses and humans, the subdirectories would be one horse and one human subdirectory containing the associated images. Within the ImageDataGenerator method, we can use an argument called rescale to normalize the data. The input for this argument looks like rescale = 1/# where # is the max byte value of the images (the range). By normalizing the data, all values fall between 0 and 1. ImageDataGenerator works with a method called flow_from_directory(directory), which extracts images from a directory. This directory is specified in the input specification for this method. Here we specify the parent directory name (examples: train_dir or validation_dir) that contains the appropriate subdirectories (such as horses and humans). Target_size is the size of the images from the generator in this format –> (pixels,pixels,bytes per pixel)- this is important becuase it will allow images to be resized to the specification that the model is trained to work on. Batch_size denotes how many images are in each batch, class_mode = ‘binary’ or ‘categorical’ (binary if we have 2 classes, categorical if more). ImageDataGenerator() can be applied to both training and testing sets and the inputs will be the same except for the directory name and batch size.
Question 2: The horses and humans CNN has 3 convolutional layers (each containing Conv2D and MaxPooling2D), 1 flatten layer which compresses the data into 1D so it can pass through the following 2 dense layers. Becuase the data is binary (2 classes), the output layer’s (the last dense layer’s) activation is sigmoid, which specifies that, if the probability of an image being of a human is greater than 0.5, the image is classified as a human and if less than 0.5, the image is classified as a horse. When compiling the model, binary_crossentropy was passed in for the loss function since we are working data containing 2 classes. RMSprop was used for the optimizer with a learning rate of 0.001 (the learning rate defines how the mathematical functions in the transformers can learn using gradient descent). As per usual, metrics was set for accuracy. The images the model trained and tested on are imperfect in comparison to the fashion mnist and numbers mnist datasets so the model is fairly inacturate. We can also tell that the model is overfit because it reached a training score of 100% while the validation score remained at a low ~75%. Luckily, the model decided that an image of myself was, in fact, a human with ~97% certainty. After changing the number of convolutions in the second layer from 64 to 32, the validation accuracy increased from ~74.6% to ~81.6% and by adding an additional layer, the accuracy further increased to ~81.6%. One important component of the convolutional layers is the max_pooling2D method, which decreases image quality while retaining important features. This helps the model train faster and more accuratly (it’s almost like a highlighter). Max_pooling2D filters an image by performing calculations for newpixel values based on a filter of given weights and each pixel’s neighbors. Pixels on the edges of an image do not have neighbors on all 4 sides so these outer 2 columns and 2 rows are removed with every rendition of pooling (reduces the dimension by 2 in each direction each time).
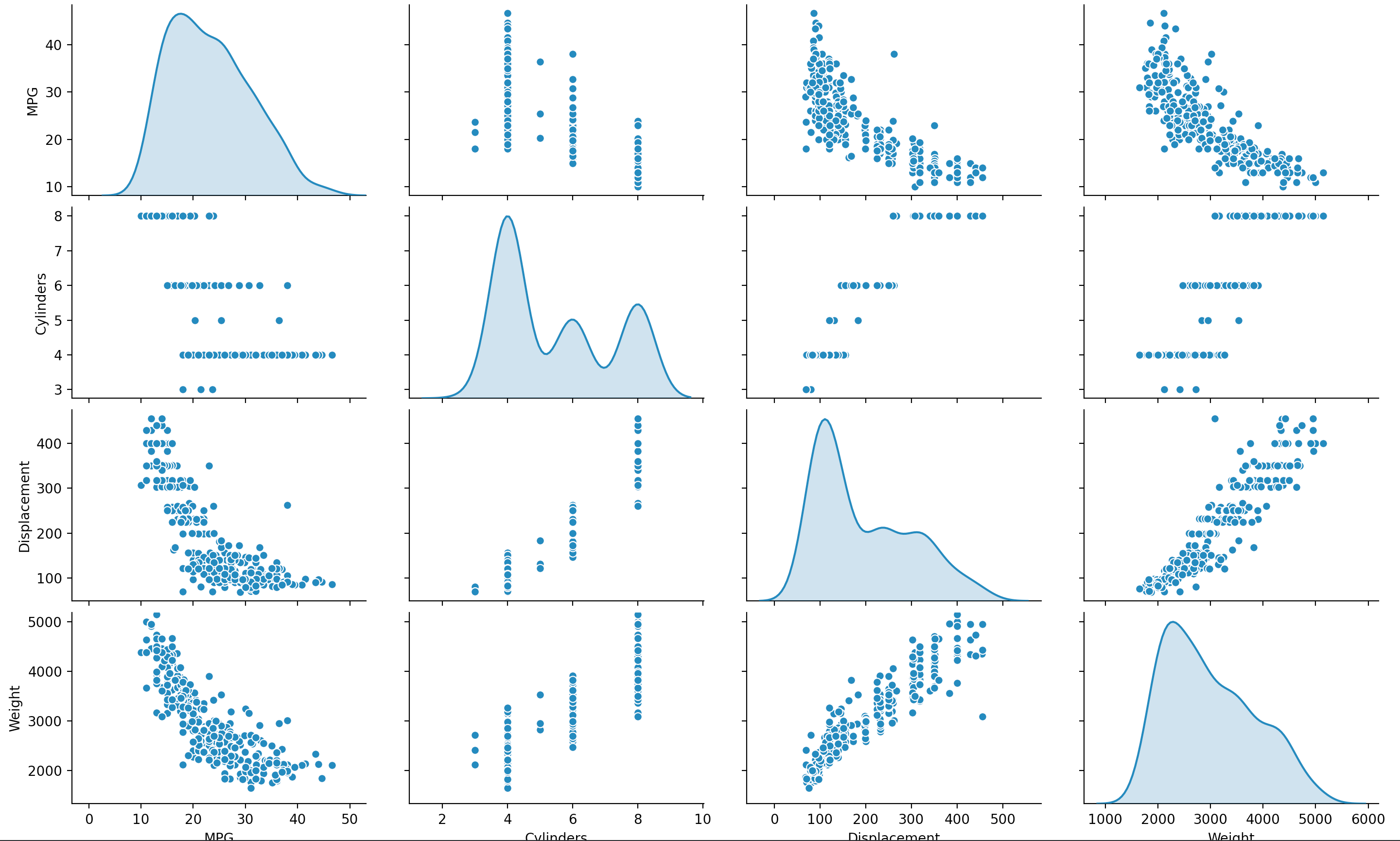
Question 3: Below is a pairwise plot, which graphs the relation between each of the four variables in a variety of plot styles. Pair plots allow us to visually look for trends in the data. Different kinds of dependence relationships amoungst these features will appear differently. For example, in this pair we might guess that there is some positive linear correlation between displacement and weight. There also appears to some relation between MPG and both weight and displacement that resembles the graph of y = $e^-x$ +c
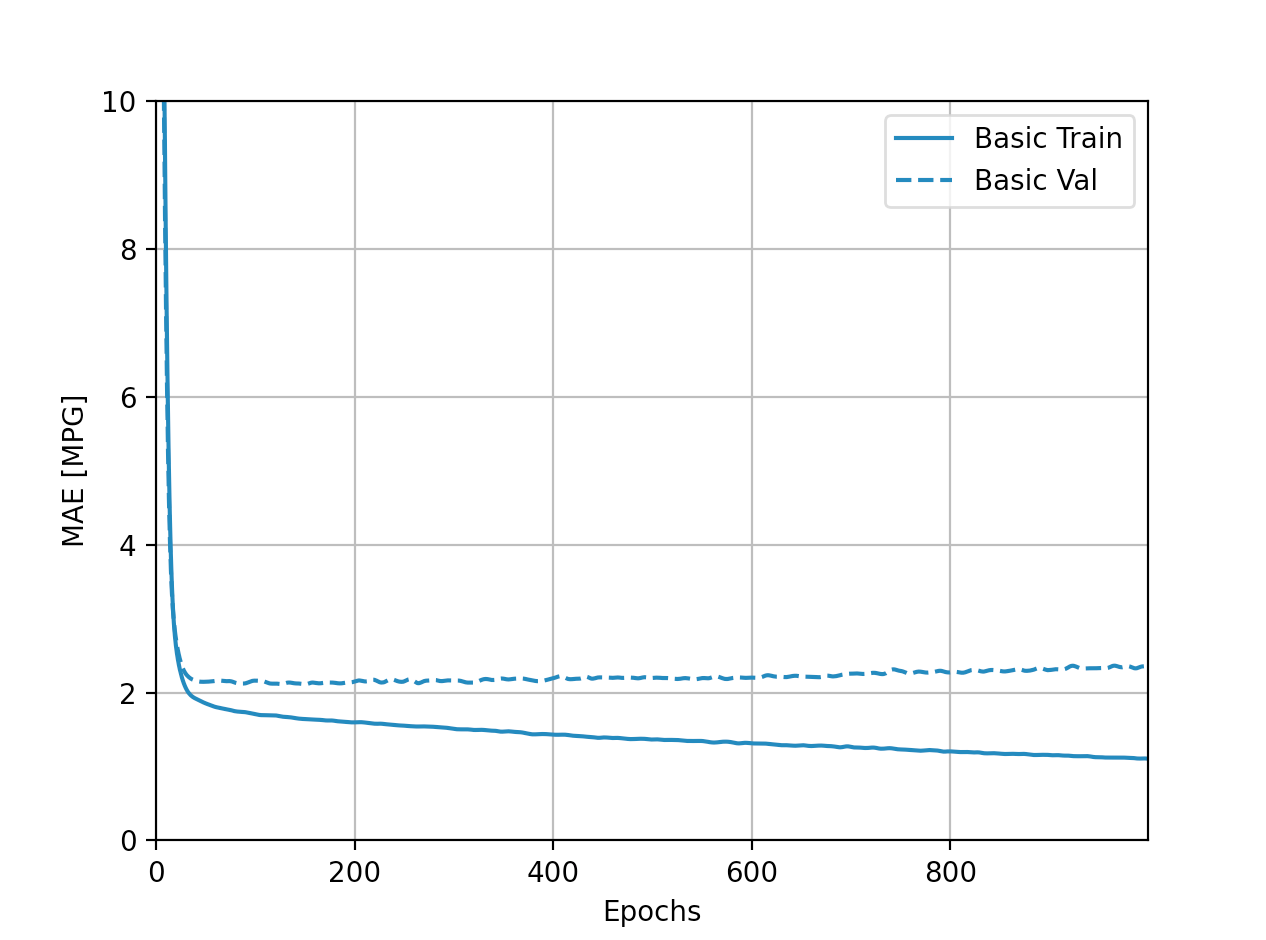
Question 4: In this model, as epochs increase, validation accuracy decreases over the last 5 epochs of training so the overall model performace is decreasing, meaning it is likely becoming overfit. Perhaps the model would benefit from training with fewer epochs.